TOC
- 자바스크립트 엔진이란?
- V8엔진
- V8엔진에는 원래 두개의 컴파일러가 있었다(과거)
- V8엔진은 여러 개의 쓰레드를 사용한다.
- 인라이닝(Inlining)
- 히든클래스(Hidden Class)
- 인라인 캐싱
- 머신코드로의 컴파일
- 가비지 컬렉션
- 이그니션과 터보팬
- 어떻게 최적화된 자바스크립트 코드를 작성할 것인가
자바스크립트 엔진이란?
자바스크립트 코드를 실행하는 프로그램 혹은 인터프리터를 말한다.
자바스크립트 엔진은 표준적인 인터프리터로 구현될 수도 있고 혹은 자바스크립트 코드를 바이트코드로 컴파일하는 JIT( just-in-time) 컴파일러로 구현할 수도 있다.
V8엔진

처음 V8엔진은 브라우저 내부에서 자바스크립트의 수행속도의 개선을 목표로 만들어졌다. 속도향상을 위해서 V8은 인터프리터를 사용하는 대신에 머신코드로 번역한다.
JIT 컴파일러를 구현함으로써 코드 실행 시에 자바스크립트 코드를 머신코드로 컴파일하는데 V8은 바이트코드와 같은 중간 코드를 생산하지 않는다.
- 머신코드: 기계어 / 낮은 수준의 언어
- 바이트코드(Bytecode, portable code, p-code): 특정 하드웨어가 아닌 가상 컴퓨터에서 돌아가는 실행 프로그램을 위한 이진 표현법이다.
V8엔진에는 원래 두개의 컴파일러가 있었다(과거)
- 풀코드젠: 간단하고 매우 빠른 컴파일러로서 단순하고 상대적으로 느린 머신 코드를 생산한다.
- 크랭크샤프트: 좀 더 복잡한 JIT 최적화 컴파일러로서 고도로 최적화된 코드를 생산한다.
V8엔진은 여러 개의 쓰레드를 사용한다.
- 메인쓰레드: 코드를 가져와서 컴파일하고 실행하는 곳.
- 컴파일을 위한 별도의 쓰레드가 있어서 이 쓰레드가 코드를 최적화하는 동안 메인 쓰레드는 쉬지 않고 코드를 수행할 수 있다
- 프로파일러 쓰레드: 어떤 메소드에서 사용자가 많은 시간을 보내는지 런타임에게 알려주어 크랭크샤프트가 이들을 최적화할 수 있게 해준다
- 가비지컬렉터 스윕을 처리하기 위한 몇 개의 쓰레드가 있다
자바스크립트 코드를 처음으로 수행할 때 V8은 풀코드젠을 이용해서 파싱된 자바스크립트 코드를 변형없이 머신코드로 번역한다. 이로 인해 머신코드의 실행을 매우 빠르게 시작할 수 있다.
이렇게 머신코드로 번역을 바로 해버리면 중간에 인터프리터가 필요없게 된다.
코드가 얼마간 수행되면 프로파일러 쓰레드(어떤 메소드에서 많은 시간을 보냈는지)는 충분한 데이터를 얻게 되고 어떤 메소드를 최적화할지 알 수 있게 된다.
그러면 크랭크샤프트가 다른 쓰레드에서 최적화를 시작한다. 크랭크샤프트는 자바스크립트의 추상구문트리(AST)를 고수준 정적 단일 할당(static single-assignment, SSA)으로 번역하는데, 이를 하이드로젠(Hydrogen) 이라고 부른다.
또한 크랭크샤프트는 하이드로젠 그래프를 최적화하고자 노력한다. 대부분의 최적화가 이 수준에서 이루어진다.
인라이닝(Inlining)
첫 번째 최적화는 미리 가능한 많은 코드를 인라이닝(inlining) 하는 것이다. 인라이닝이란 호출 지점(함수가 호출된 곳의 코드 위치)을 호출된 함수의 내용으로 바꾸는 과정입니다. 이러한 단순한 과정으로 이후의 최적화가 더욱 큰 의미를 가지게 된다.
히든클래스(Hidden Class)
자바스크립트는
- 프로토타입 기반의 언어: 클래스라는 것은 없으며, 객체는 복제 과정을 통해 생성된다.
- 동적언어(dynamic programming language): 객체가 생성된 이후에도 속성을 쉽게 추가하거나 삭제할 수 있다.
- 대부분의 자바스크립트 인터프리터: 딕셔너리와 유사한 구조(해쉬함수 기반)를 이용해 객체 속성 값의 위치를 메모리에 저장한다.
속성값(혹은 이들 속성을 가리키는 포인터)은 메모리에 고정된 오프셋을 가진 연속적인 버퍼로 저장될 수 있고 오프셋의 길이는 속성 타입에 따라 쉽게 결정될 수 있습니다. 하지만 이런 것들이 속성 타입이 동적으로 변할 수 있는 자바스크립트에서는 불가능하다.
딕셔너리를 이용해서 메모리 상에서 객체 속성의 위치를 찾아내는 것은 매우 비효율적인 일이기 때문에 V8에서는 다른 방법을 이용합니다. 바로 히든클래스(hidden classes) 다.
히든클래스는 자바와 같은 언어에서 사용되는 고정 객체 레이아웃과 유사하게 작동하는데 다만 런타임에 생성된다는 차이점이 있다. 이들이 실제로 어떤 모습인지 살펴보자.
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
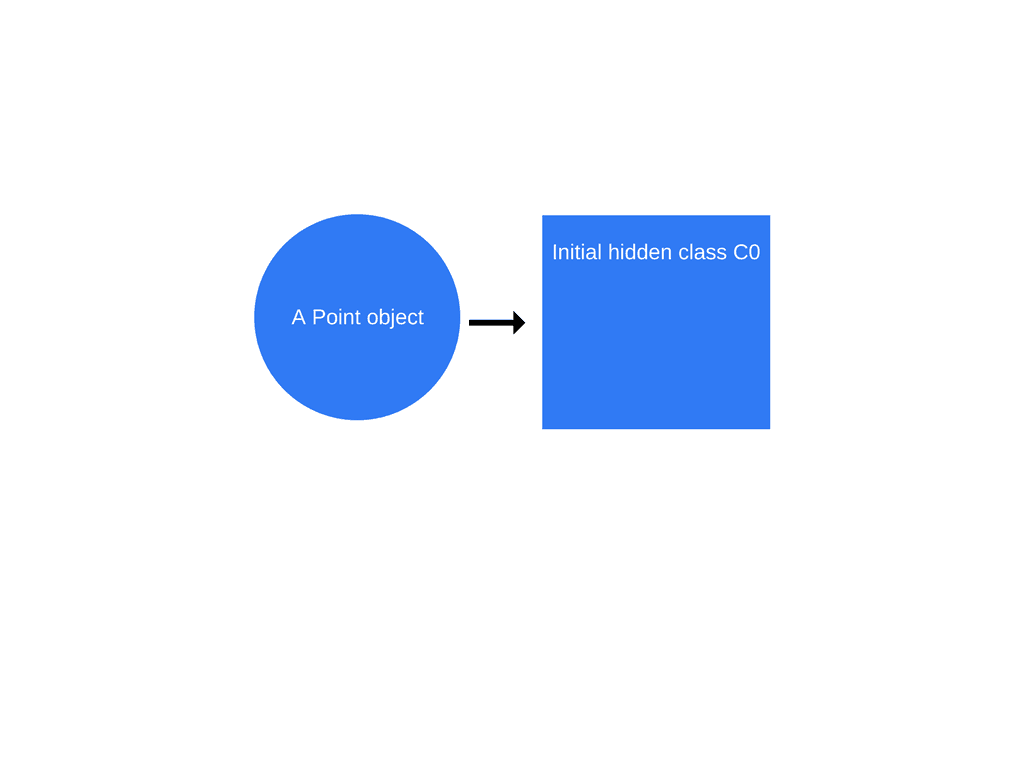
- new Point(1, 2)이 실행되면 V8은 이라는
C0히든클래스를 생성
2.this.x = x가 수행되면(Point 함수 내에서) V8은 C0을 기반으로 C1이라는 두 번째 히든 클래스를 생성
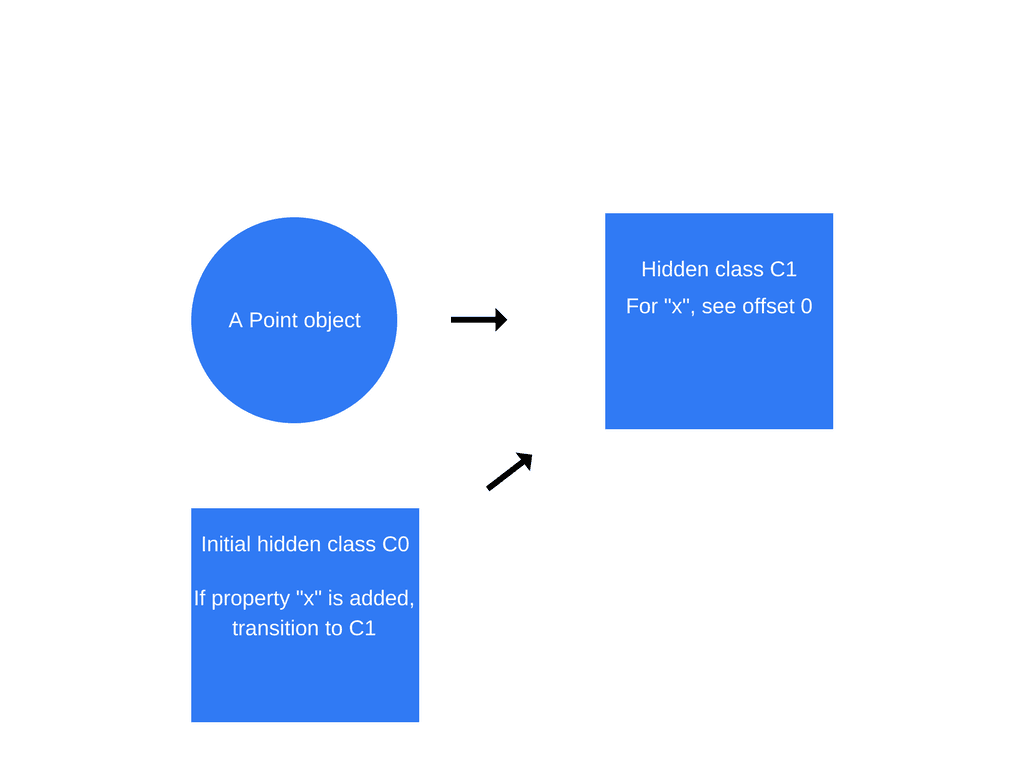
히든클래스 전환이 중요한 이유는 이를 통해 히든 클래스가 같은 방식으로 생성된 객체들 사이에 공통으로 사용될 수 있기 때문이다. 만약 두 개의 객체가 하나의 히든클래스를 공유하고 같은 속성이 이들에게 추가되면 전환과정은 이들 객체가 동일한 새로운 히든클래스를 받도록 하고 그에 따라 그에 딸려 오는 최적화 코드도 모두 동일하다.
- 이 과정은
this.y = y가 수행될 때도 반복된다(마찬가지로 Point함수 내에서this.x = x구문 뒤에서).
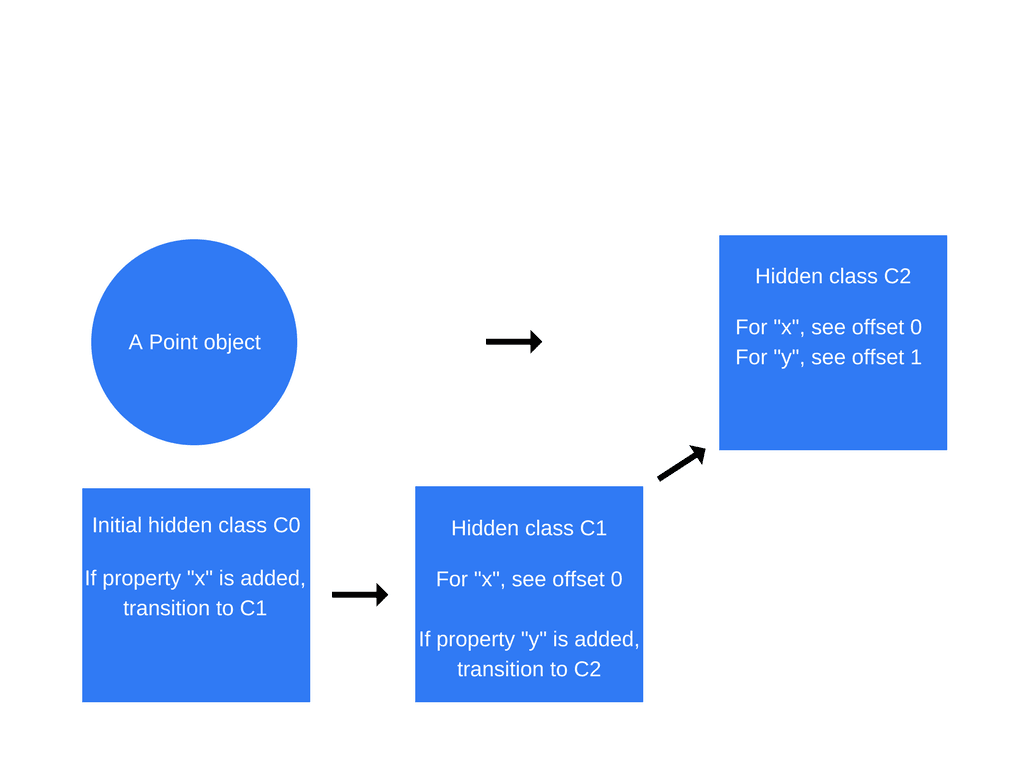
히든클래스 전환은 속성이 객체에 추가되는 순서에 의존적이다.
function Point(x, y) {
this.x = x;
this.y = y;
}
var p1 = new Point(1, 2);
p1.a = 5;
p1.b = 6;
var p2 = new Point(3, 4);
p2.b = 7;
p2.a = 8;
아마도 p1과 p2에 대해 같은 히든클래스와 전환이 사용될 것이라고 생각할지도 모르겠지만 실제로는 그렇지 않다. p1에서는 속성 a가 추가되고 그 다음 b가 추가된다. 하지만 p2의 경우 b가 먼저 할당되고 a가 할당된다. 따라서 p1과 p2는 서로 다른 히든클래스를 사용하게 되고 결국 전환 경로도 달라진다.
결국 동적속성을 같은 순서로 초기화하는 것이 훨씬 좋다. 그래야 이미 만들어진 히든클래스를 재사용하게 됨으로 최적화에 좋다.
인라인 캐싱
같은 메소드에 대한 반복되는 호출은 같은 타입의 객체에 이루어진다는 관찰 결과에 의존한다.
- 인라인 캐싱은 어떻게 작동할까요?
V8은 최근 메소드 호출에 파라미터로 전달된 객체 타입의 캐시를 유지하고 이 정보를 이용해 앞으로 파라미터로 넘어올 객체의 타입에 대한 가정한다. 만약 V8이 메소드에 전달될 객체 타입에 대한 가정을 잘 할 수 있으면 객체의 속성에 접근할 방법을 알아내는 과정을 수행하지 않아도 되며 그 대신 객체의 히든 클래스에 대해 이전에 찾아서 저장했던 정보를 사용할 수 있다.
- 히든클래스와 인라인 캐싱의 개념은 서로 어떻게 관련 있을까?
특정 객체에 메소드가 호출될 때마다 V8엔진은 특정 속성에 접근하기 위한 오프셋을 계산하기 위해 해당 객체의 히든클래스를 찾아봐야 한다. 동일한 히든 클래스의 동일한 메소드에 대해 두 번의 성공적인 호출을 마치고나면 V8은 히든클래스를 찾는 것을 생략하고 단순하게 스스로 해당 객체 포인터에 속성 오프셋을 더한다. 이후 해당 메소드에 대한 모든 호출에 대해 V8은 히든클래스는 변하지 않았다고 가정하고 이전에 찾아 두었던 오프셋을 이용해 직접 메모리 주소로 점프한다. 이를 통해 실행 속도는 크게 증가한다.
- 인라인캐싱은 같은 타입의 객체가 히든클래스를 공유하는 게 중요한 이유
만약 타입은 같고 히든 클래스는 다른 두 객체를 만들면 (앞서의 예제처럼) V8은 인라인캐싱을 사용할 수 없을 것이다. 왜냐하면 두 객체가 같은 타입이기는 해도 각각에 대응하는 히든클래스가 그들의 속성에 서로 다른 오프셋을 할당하기 때문이다.

두 객체가 기본적으로 동일하지만 ‘a’와 ‘b’ 속성은 서로 다른 순서로 생성되었다.
머신코드로의 컴파일
하이드로젠 그래프가 최적화되면 크랭크샤프트는 이를 리튬이라고 부르는 더 하위레벨로 낮춘다. 리튬의 대부분의 구현은 아키텍쳐에 따라 다르다. 레지스터 할당이 이 수준에서 이루어진다.
마침내 리튬은 머신 코드로 컴파일된다. 그런 다음 OSR(on-stack replacement, 온스택교환)이라는 것이 일어난다. 분명하게 수행시간이 긴 메소드를 컴파일하고 최적화하기 전에 그것을 실행할 가능성이 높다. V8은 더 최적화된 버전으로 다시 시작하기 위해 방금 어떤 코드가 느리게 수행됐는지 잊지 않을 것이다. 대신 우리가 가진 모든 맥락(스택, 레지스터 등)을 전환하여 코드의 수행 중간에 최적화된 버전으로 옮겨탈 수 있도록 해준다. 이를 V8이 시작부터 코드를 인라인하고 기타 최적화를 수행한 것을 생각하면 매우 복잡한 작업이다.
V8엔진이 내린 가정이 더 이상 유효하지 않는 경우에 대비해 반최적화(deoptimization)라는 보호장치가 존재한다. 이는 반대로의 변형을 수행하여 최적화되지 않은 코드를 되돌려 놓는다.
가비지 컬렉션
가비지컬렉션을 대해 V8은 전통적인 마킹하고 쓸어버리기(mark-and-sweep)의 세대적 접근방법을 이용해 예전 세대를 제거합니다. 마킹 단계에서는 자바스크립트의 수행을 중단하게 되어있다. 가비지컬렉션 비용을 통제하고 그 수행을 좀 더 안정적으로 하기위해 V8은 점진적 마킹을 이용한다. 힙 전체를 훑어서 가능한 모든 객체를 마킹하는 대신 힙의 일부만을 확인한 다음 정상적인 자바스크립트 실행을 계속한ㄴ다. 그 다음의 GC 수행은 바로 이전에 멈춘곳에서부터 계속된다. 이를 통해 일상적인 실행에는 매우 짧은 코드 중단만 일어난다. 위에 언급한대로 쓸어버리기는 별도의 쓰레드에서 수행된다.
이그니션과 터보팬
2017년 초 V8 5.9의 배포와 더불어 새로운 실행 파이프라인이 소개되었다. 새로운 파이프라인은 더 큰 성능 향상을 가져오며 실제 자바스크립트 응용프로그램에서 현저하게 메모리를 절약할 수 있다.
- V8의 인터프리터: 이그니션
- 새로운 최적화 컴파일러: 터보팬
이 주제와 관련한 V8팀의 블로그는 여기에서 확인하실 수 있다.
V8의 5.9 버전이 출시된 이후, 풀코드젠과 크랭크샤프트(2010년부터 V8에서 사용되고 있던 기술들)는 V8에서 자바스크립트 실행에 사용되지 않고 있ㄴ다. 왜냐하면 V8팀이 새로운 자바스크립트 언어 기능과 이러한 기능에 필요한 최적화 필요에 대응하는데 애를 먹고 있기 때문입니다.
이는 V8의 구조가 앞으로는 훨씬 단순하고 유지보수가 용이하게 되었다는 것을 의미한다.
어떻게 최적화된 자바스크립트 코드를 작성할 것인가
-
객체 속성의 순서: 객체 속성을 항상 같은 순서로 초기화해서 히든클래스 및 이후에 생성되는 최적화 코드가 공유될 수 있도록 한다.
-
동적 속성: 객체 생성 이후에 속성을 추가하는 것은 히든 클래스가 변하도록 강제하고 이전의 히든클래스를 대상으로 최적화되었던 모든 메소드를 느리게 만든다. 대신에 모든 객체의 속성을 생성자에서 할당한다.
-
메소드: 동일한 메소드를 반복적으로 수행하는 코드가 서로 다른 메소드를 한 번씩만 수행하는 코드 보다 더 빠르게 동작합니다(인라인 캐싱 때문)
-
배열: 값이 띄엄띄엄 있어서 키가 계속해서 증가하는 숫자가 되지 않는 배열은 피하는게 좋다. 모든 요소를 가지지는 않는 배열은 해시테이블이다. 이와 같은 배열의 요소들은 접근하기에 많은 비용이 든다. 또한 커다란 배열을 미리 할당하지 않도록 하십시오. 사용하면서 크기가 커지도록 하는 게 낫다. 마지막으로 배열의 요소를 삭제하지 말기. 그 배열의 키가 띄엄띄엄 배치된다.
-
태깅된 값: V8은 객체와 숫자를 32비트로 표현한다. 어떤 값이 오브젝트(flag = 1)인지 혹은 정수(flag = 0)인지는 SMI(Small Integer)라는 하나의 비트에 저장하고 이 때문에 31비트가 남는다. 따라서 어떤 숫자가 31비트 보다 크면 V8은 이 숫자를 분리해서 더블 타입으로 전환한 다음 이 숫자를 넣을 새로운 객체를 생성한다. 이러한 동작은 비용이 높으므로 가능한 31비트의 숫자를 사용하도록 하십시오.